戦場におけるフリー・ジャズ -GhostPlayのAIアプローチはどのように防空を強化するか- (Defense AI Observatory)
先に掲載した「主従関係 -ドイツにおける防衛AIの状況- (Defense AI Observatory)」は、ドイツにおける防衛AIに関わるドイツ特有の状況について述べられたものであった。今回は、同じくDefense AI Observatoryの論文で、先の論文でも触れられているGhostPlayというプロジェクトで取り組まれている「戦場におけるAI戦術の役割」を取り上げた白書3部作のうちの2022年に発表された最初の論文『Free Jazz on the Battlefield』を紹介する。この論文は、戦場におけるAI戦術についての核となる考え方を示し、基本的な手法の重要な側面(例えば、分散化された非階層的な指揮・統制の使用など)を説明し、攻撃的なスウォームに対する防空の役割に焦点を当てた最初の調査結果を発表したものとなっている。戦場でのAIの活用について検討する際の参考となると考える。
なお、GhostPlayのサイトによるとは、GhostPlayとは、複雑な軍事的交戦のためのAIを基盤とする戦術をマシン・スピードで訓練、視覚化、分析するための戦場のバーチャル・ツインである。「”Ghost”は現実の高性能バーチャル・ツインである。”Play “は、このようなバーチャル・ツインにおいて、AIが制御する赤と青のフォース・プラットフォーム・アバターの振舞いを実証すると記されている。(軍治)
![]()
戦場におけるフリー・ジャズ
GhostPlayのAIアプローチはどのように防空を強化するか
Free Jazz on the Battlefield
How GhostPlay’s AI Approach Enhances Air Defense
Heiko Borchert, Christian Brandlhuber, Armin Brandstetter, and Gary S. Schaal
DAIO Study 22|03
1 まとめ
現在の紛争は、侵略者(aggressor)の航空戦力を遠ざけ、同盟国の機動の自由(freedom of maneuver)を確保するための統合防空システム(IADS)の重要性を強調している。しかし、侵略者が従来の消耗攻撃(attrition attacks)で何百もの無人航空機アセットを使って同盟国の防空を飽和させ、欺瞞し、無力化したり、人工知能(AI)によって強化された可能性のあるこれまで未知の戦術を適用したらどうなるのだろうか?
GhostPlayは、さまざまな野心的レベルで活動し、未知の戦術や新たな戦術を活用することに優れ、作戦のテンポを自分たちの利益のために利用しようと努力する侵略者に対して、戦術的な軍事的意思決定を支援する防衛意思決定アルゴリズム(Play)を開発することによって、この問題に対処している。GhostPlayは合成シミュレーション環境(Ghost)を使用し、AIを強化したソリューション(スタンド・アロンまたはフェデーレート・システムで動作)が、作戦テンポを加速し、戦術レベルのパフォーマンスを強化し、将来の敵対的振舞い(adversarial behavior)を予測する取組みを強化するために使用できるかどうか、またどの程度使用できるかを評価する。
防衛イノベーションに関する文献の増加を背景に、本稿では、統合防空システム(IADS)を基盤とする防護を確保し、拡張するための斬新な戦術を利用する、文脈と結果を認識するAIシステムを開発するというGhostPlayの到達目標について論じる。本稿では、GhostPlayのコンセプト的・技術的セットアップに光を当て、シミュレーションに基づく初期の発見を要約し、将来の開発オプションについて概説する。
2 イノベーションがソリューションなら、問題は何か?
「軍事イノベーション」はNATOとEU加盟国の間でホットな流行語となっている。このような防衛イノベーション(defense innovation)に関する言説を形成しているのは、2つの力である。第一に、敵対的な軍事力の主張がますます強まっているため、戦略的競争相手に対して優位を保つために同盟国の防衛イノベーションの必要性が強調されている[1]。第二に、防衛イノベーションの言説は、人工知能(AI)、自律型ロボットシステム、宇宙、量子技術など、新興技術の重要な役割を強調している[2]。ほとんどの場合、防衛エコシステムの一部ではない営利主体が、これらの技術の開発と応用のフロント・ランナーとなっている。このため、新たなプレーヤー、技術、基盤となる能力を防衛産業・技術基盤に統合する必要性が高まっている。
流行とはいえ、国防のイノベーションを定義するのは難しい[3]。軍隊(armed forces)にどのようなイノベーションが期待され、それぞれの任務を達成するために何を変える必要があるのか、正確に記述された基本文書(capstone documents)はほとんどない。我々は先行研究に基づき[4]、防衛イノベーションとは、軍隊(armed forces)が軍事力行使の準備と遂行方法を変える、コンセプト的・文化的、組織的、技術的な新しさを説明するものだと主張する。そうすることで、軍隊(armed forces)は過去の作戦経験と要件を基礎とする。これら3つのベクトルを背景に、GhostPlayのイノベーション理解は2つある。
第一に、GhostPlayは、冷戦終結後、ほとんどのEU/NATO諸国において敵防空制圧(SEAD)能力が萎縮していることから、差し迫ったギャップに対処する。我々は、AIを基盤とするソリューションが敵防空制圧(SEAD)任務を実施するために無人航空機(UAV)のスウォームをどの程度まで増強できるかを探求する。第二に、GhostPlayは既存の技術を補強するための新しい技術には注目していない。むしろ、新技術の使用が戦術レベルでの斬新な戦場の振舞いを誘発する方法に注目している。GhostPlayは、これら2つの側面を念頭に置き、防空(AD)および侵略者のスウォームに対する斬新なAIを基盤とするソリューションをモデル化し、互いを凌駕する方法を学習する。本稿で取り上げる最初のプロジェクト・フェーズでは、防御側に焦点を当てる。
無人航空機(UAV)のスウォームに耐え、対抗する優れた戦術的防空(AD)の振舞いをモデル化し、学習するために、我々は2つの主要な側面を考慮する。第一に、最近の紛争では無人航空機(UAV)が防空(AD)に対して優位に立ち、防空(AD)のソリューションが脆くなっている[5]。脆さは、強力な防空(AD)フェデレーション※1を作るために、関連するすべてのセンサーとエフェクターが適切に統合されていないことに起因する。統合には調整が必要だ。これが2つ目の要素である。GhostPlayは、侵略者を撃退するための戦術的防空(AD)の汎用性を高める斬新なアプローチに焦点を当てている。そうすることで、GhostPlayは、中央の階層的な指揮・統制(C2)ソリューションの助けを借りずに、センサーやエフェクターのようなシングルのエンティティを創発的な振舞い(emergent behavior)によって調整する連携防空(AD)ウェブを開発するオプションを模索することで、新境地を切り開く。セクション3.2で説明するように、GhostPlayは、敵対者がターゲットとし攻撃できるような専用のシステムに指揮・統制(C2)を委譲するのではなく、防空(AD)ウェブの各要素に指揮・統制(C2)機能を組み込む。このアプローチにより、防空(AD)ウェブは、脅威や任務要件への対応において、より流動的で俊敏かつ弾力的なものとなる。
※1 フェデレーションとは、相互作用するモデル、シミュレーション、およびシステムで描写されるオブジェクトを共通理解に基づいて取り扱えるための共通のインフラストラクチャとすること。
優れた戦術的汎用性(tactical versatility)は、軍事行動の自由を増強する。この目的のために、GhostPlayは、軍事力がどのように適用されるかを導き、知らせる戦争の原則(principles of war)を活用しようとしている[6]。とりわけ、GhostPlayは以下のことに努める。
- 時間と場所におけるエフェクターの使用を最適化し、どのような状況下でも最適な効果を達成するために部隊をどのように編成するかに関しても最適化することで、取組みの経済性を追求
- 攻撃側がまだ目撃していない戦術的振舞い(tactical behavior)を生み出すような方法で、創発的な振舞い(emergent behavior)を利用することによる奇襲
- 敵対者と交戦するために同盟部隊を先制的に配置することを到達目標に、将来の敵対的動きを予測することによって、主導権を握る
まとめると、GhostPlayは、戦術的な汎用性を高めるために、まず航空防衛のために、そして後の段階では敵防空制圧(SEAD)任務を遂行する無人航空機(UAV)のスウォームに対しても、斬新な戦場の振舞いを可能にする技術を開発することで、防衛イノベーションに貢献している。この点で、GhostPlayのイノベーションはフリー・ジャズ(free jazz)のように即興的であり、外部からの刺激に反応し、ダイナミックであり、文脈と結果を意識した新世代の調整メカニズムを活用することで、防空(AD)任務を達成するために利用可能なあらゆるアセットを統合する。
3 GhostPlayの新機軸:フリー・ジャズ対中央での調整
GhostPlayは、将来の防空(AD)コンセプトのための具体的な利点や能力向上というイノベーションの創出に努める一方で、このプロジェクトの基礎技術は、現代のAI研究において最も困難なトピックのひとつである、他の機械や人間と協力して戦術的振舞い(tactical behavior)を学習する能力に貢献している。これには3つの能力が必要である。第一に、状況を適切に評価し、敵対的な振舞いを予測する能力。第二に、時間を延長したシナリオや敵の行動に対応して、目標を達成するためにシステムの行動を編成・組織化する方法を学習する能力。これには、防衛システムの行動に対して関連する環境がどのように反応するかを評価する能力も含まれる。第三に、複雑な課題をパートナーと協力して解決するために、いつ、どのように協力すべきかをシステムが自ら学ぶよう動機付ける能力である。これらの能力は、機械対機械、機械対人間の相互作用における技術的自律性を目指す将来のソリューションを支えるものである。
現在、AlphaGo、Alpha Star、Open AIのような深層強化学習(Deep Reinforcement Learning)ソリューションが超人的な能力を持っているという考えは、かなりの誇大広告を生み出している。しかし、これらのシステムは、よく知られた完全に安定した環境でコンピュータ・ゲームをプレイする。それとは対照的に、軍事的ソリューションは、不測の事態が発生する非定常の実世界環境で作動する。さらに、敵対的な意図や能力に応じて、軍事ゲームのルールは非常に迅速に変化する可能性がある。
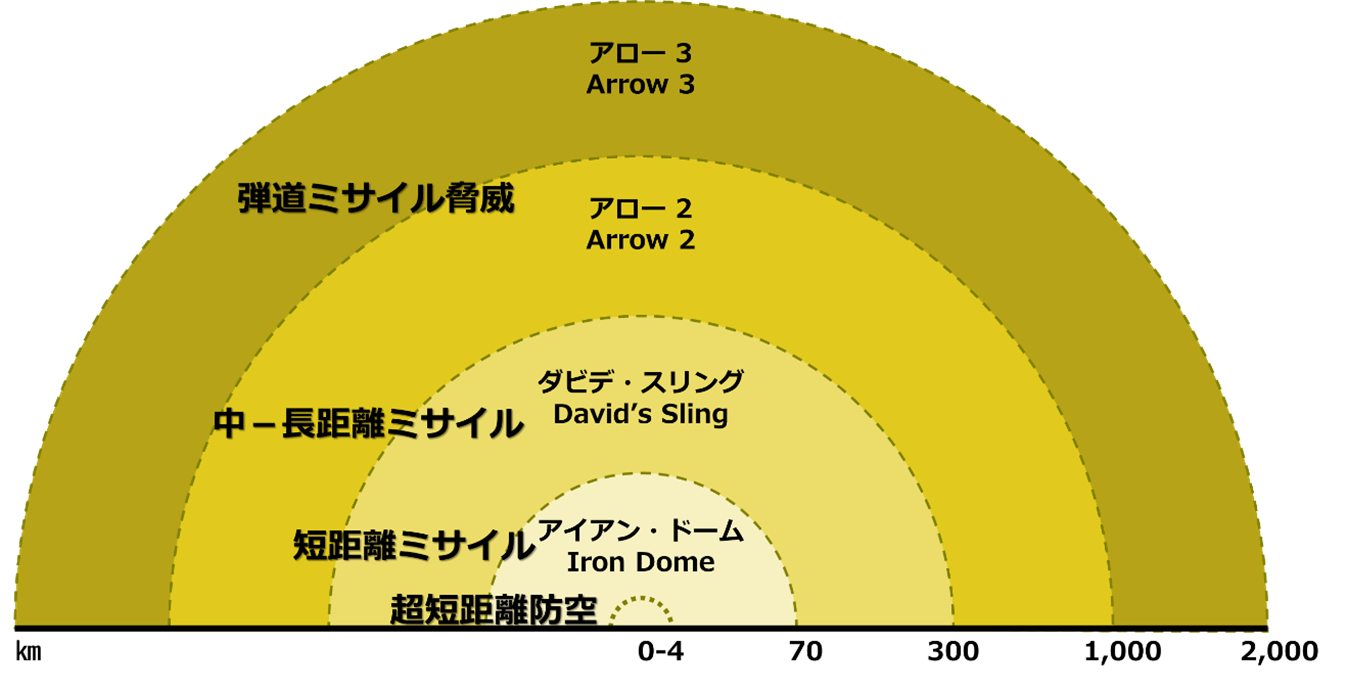
これはGhostPlayが動作することになっている環境である。統合防空ソリューション(IADS)は階層化アプローチ(layered approach)を採用している(図1)※2。センサーとエフェクターの到達範囲(reach)は、超短距離防空(VSHORAD)、短距離防空(SHORAD)、中距離防空(MRAD)、長距離防空(LRAD)の地上を基盤とする「各ドーム(domes)」を設定するのに役立つ識別子(discriminator)である。
※2 図1中の防空システムの射程について:インターネットによると、アイアン・ドーム(Iron Dome):50~70km、ダビデ・スリング(David’s Sling):40〜300km、アロー2(Arrow 2):公式では70km、推定では90km~150km、アロー3(Arrow 3):~2,400kmとなっている。この論文の引用先は下記の図のようになっている。
| 図1:防空への階層化アプローチ
出典:ウパル『イスラエル、短・中・長距離弾道ミサイルの弾幕を防御する多層防空システムの試験に成功』。 |
今日、特定のシステムは、それぞれの「ドーム(dome)」に対して異なるセンサーとエフェクターを統合している。各システムは孤立して開発されている。統合を達成するための統治原理は、階層的かつ中央集権的である。中央の指揮・統制(C2)が各システムを動かし、複数の発射装置を調整するノードを持つ階層構造に報告する。最終的には、高レベルの指揮・統制(C2)または指揮・統制・通信・コンピュータ(C4)システムがすべての要素を統合し、調整する。試行錯誤が繰り返されたとはいえ、このシステムは静的で、非常にもろく、センサーからエフェクターまでの待ち時間が不満足なものになることが多い。
現代の最先端ソリューションは、OODA(観察(observe)-志向(orient)-決心(decide)-行動(act))サイクルの個々の処理ステップを改善するためにAIを使用することがある。GhostPlayは、OODAワークフローにおける個々のステップの自動化を超えている。むしろ、GhostPlayのポリシーは、意思決定を大幅に加速し、センサーからエフェクターまでの待ち時間を短縮しながら、きめ細かく将来を見据えた確率的最適統制体制を確立する。
GhostPlayアーキテクチャは、複数の同時統制プロセス(「エージェント(agent)」)を仲介することでこれを実現する。各プロセスは、例えばセンサーやエフェクターのような物理システムを効果的に統制したり、特定の行動計画を決定したりするために、特化した統制戦略(「ポリシー(policy)」)を実行する。GhostPlayのエージェントは一元的に調整されているわけではない。むしろ、共通の行動規範(common behavioral conventions)(「遭遇のルール」)を用いて、パートナーと連携して共通の目標を達成するための訓練(マルチエージェント学習)を行いながら、調停と情報交換を確保する。既存の防空(AD)ソリューションとは対照的に、GhostPlayはプラットフォーム上でパイプライン化されたデータ融合プロセスを持たない。この具体的なデザインの選択は、防衛ソリューションが創発システムとして開発できるかどうかを探求する野心に突き動かされている。
3.1 戦術AI:基本的な構成要素
最先端の防衛AI
現在、最先端の防衛AIは、個々のOODA段階をサポートするAI技術やAIを基盤とする構成物を導入することに重点を置いている。例えば、現在のアプリケーションは、空中偵察写真のオブジェクトを検出して分類したり、電磁スペクトルの特性を分類して潜在的な放射体を推測したりする。その際、OODAループは(線形)パイプライン処理を実行する。したがって、配備されたAIシステムは、シングル・ステップの決心のみを実行すれば十分である。例えば、センサーがビデオ・シーケンスをストリーミングする場合、光学センサーは画像またはシングルのビデオ・フレームを取得する(観察)。この画像は、オブジェクトを検出し分類しようとするAI構成物に送られる(志向)。AI構成物はベイズ分類器と解釈することができ、入力画像とAI構成物が学習したパラメータ(多くの場合はニューラル・ネットワークの重み)に基づいて、ある(既知の)オブジェクトが存在する確率を決定する。現在、AI分類器は、このように1ステップの入力から出力へのマッピングを実装している。
非悪性環境や戦争の霧の中での分類と識別の向上
実世界のほとんどのアプリケーションでは、環境の影響を統制することができない[7]、あるいは、さらに悪いことに、センサーが無害な環境で動作しなければならない場合、分類が文脈を考慮したセンサー統制戦略(ポリシー)に統合されていれば、より良い結果を得ることができる。光学センサーは複数のオブジェクトを示す画像を取得する。これらのオブジェクトは観察者から遠く離れているため、画像上では不特定なピクセルとしてのみ表示される。最先端のAI分類器アプローチでは、各画像を分類する必要があり、これらのターゲットのピクセルを無視することがほとんどである[8]。
対照的に、ポリシー・ベースのセンサー管理システムには異なるオプションがある。入力画像に基づいて、ポリシーは、分類のために追加のセンサー入力を必要とする潜在的なターゲットまたは脅威を表すと推定されるそれらのピクセルをズームインすることを決定することができる。システムは、例えば、雲がそれぞれのオブジェクトを隠している場合、より良い情報を得るために、関心のある位置を照らすことを決定するかもしれない。このアプローチにより、システムは安定した分類を早い段階で提供することができ、最先端のアプローチではオブジェクトを認識することさえできないずっと前に分類することができる。
この2つのアプローチの違いに注意することは非常に重要である。センサー管理と分類・識別を連動させるためには、現在のAIが行っているような入出力マッピングの学習だけでは不十分である。むしろ、システムは行動シーケンスを学習し、どのようにすれば良い分類結果をできるだけ効率的に得られるかを理解する必要がある。良い行動シーケンスを学習するためには、システムは特に、行動の即時的な影響と、起こりうる長期的な結果を理解するように学習しなければならない。数学的な観点からは、これはもはやベイズ分類タスク※3ではなく、マルコフ決定過程(MDP)※4の数学的枠組みに基づいたソリューションが必要となる[9]。
※3 ベイズ分類タスクとは、対象事象を、確率計算に基づいた統計モデルの構築手法の単純なベイズ・モデル(ベイズ推定や階層ベイズ・モデルなど)で扱えるように確率によって分類することを指す。
※4 マルコフ決定過程(MDP, Markov Decision Process)は統計学における確率過程の一種。確率過程は確率的な規則に従って変動する現象やシステムの数学的モデルを指す。そして、マルコフ決定過程は特に、未来の状態や報酬が現在の状態と現在の行動のみに依存するというマルコフ性を持つ確率過程。(参考:https://www.tech-teacher.jp/blog/markov-decision-process/)
効果を最大化し、自社船のエクスポージャー/リスクを最小化するための重要なトレードオフを学ぶ
特定の行動が即座に与える影響を理解することに加え、優れたポリシーを学習することは、システムが重要なトレードオフを行う方法を学習することも意味する。例えば、ある位置をズームインすると、観測ウィンドウが小さくなり、システムが1つのオブジェクトを衒学的に分類することに「行き詰まる(gets stuck)」一方で、高速で移動する脅威が観測ウィンドウの外側からシステムに向かっていることを認識できないという状況に陥る可能性がある。
また、システムは短期的な成功と長期的な結果のバランスを慎重に取る必要がある。たとえば、アクティブ・レーダー・センサーでターゲットを照射するという決定は、短期的な情報ニーズを満たすかもしれませんが、レーダー信号発信機がターゲットに検出され、高速対レーダー・ミサイル(HARM)が発射されて観測者を破壊する可能性があるため、観測者を危険にさらす可能性がある[10]。アクティブ・センサーを使用する利点がリスクよりも大きいかどうかは、状況の文脈に大きく依存する。さらに、アクティブ・センサーを使用するという決定は、状況がどのように展開するかに直接影響する。この複雑さを克服するシステムは、文脈に敏感で結果を認識でき、米国国防高等研究計画局(DARPA)によると、いわゆる第3波AIシステムを構成する[11]。
多くの場合、これらのシステムの訓練には深層強化学習(Deep Reinforcement Learning)が使われるが、これには技術的な課題がある。分類のためのAIのコンセプトを例にとってみよう。分類の各ラウンドの後、システムによって下される各決定には、チュートリアル入力(タグ付けされた例など)がある。しかし、それぞれの決定がシナリオにポジティブな影響を与えたかネガティブな影響を与えたかをシステムが理解できるような、システムへの即時フィードバックはない[12]。システムは長期的な報酬の摂取を最大化する必要があるが、リンクが欠落しているため、肯定的か否定的かの決心結果はシナリオの終了時にしかわからない。しかし、このことは、数千ステップ先の未来を含む可能性があり、システムが期待される適切な機能と同期しない可能性があることを意味する。
大規模なデータ・ベースを使用せずに、優れた初期ポリシーを作成する
強化学習の学習プロトコルには、シナリオを通じてトレースを収集し、いわゆる状態値V(s)や状態-行動値Q(s,a)を集約するコンセプトがある。これらのコンセプトは、状態(s)のときに行動(a)を選択したことが平均して良かったか悪かったかを示す。これらの結果に基づいて、ニューラル・ネットワーク構造がそれぞれの価値関数を表現するように訓練される[13]。ただし、実際にはこれらのコンセプトのみを使用すると、状態(s)で行動(a)を選択した場合の肯定的または否定的な結果が現在の状態だけでなく、将来の行動を導くポリシーにも依存するため、(非常に)最適ではないポリシーにつながる可能性がある。例えば、追尾レーダーはターゲットを照らし、交戦のための正確な位置と動きの推定を得るためにオンにされる。
この決心は、脅威の遮断に成功した場合にはプラスに働くかもしれない。しかし、失敗した場合、システムがその位置を露呈し、敵対的な攻撃の機会を作り出してしまうため、マイナスになることもある。さらに、より精度の低いパッシブ・センサーを使用し、暴露時間を短縮しながらターゲットを事前に割り当てることで、戦術は改善されただろう。徐々に良いポリシーに収束させるために、強化学習システムは、過去の振舞いを利用することと、新しいポリシーを提供する可能性のある新しい振舞いを探索することの間でバランスを取る必要がある。
シナリオが何千もの決定ステップに及ぶと、良いポリシーを見つけることは組み合わせ的に不可能になる。このことは、初期の訓練段階で特有の問題を引き起こす。アプリケーションが「超人的な(super-human)」意思決定能力を持つと言われてきたほとんどすべてのケースにおいて、強化改善を開始するために使用される初期ポリシーは、教師あり学習で開発されてきた。教師あり学習が可能だったのは、チュートリアル入力を作成するために、専門家レベルのポリシーの大規模なデータ・ベースが利用可能だったからである。しかし、GhostPlayが扱う軍事応用分野には、そのようなデータ・ベースがない。そのためGhostPlayは、データ・ベースなしで初期の優れたポリシーを作成する方法を見つける必要があった。
今日、GhostPlayはこの目標を達成するために、斬新な「ポリシー空間内検索技術(search-in-policy-space technique)」を実装している。我々はまず、複数のセンサーと1つのエフェクターを搭載した防空プラットフォームをモデル化することにした。各センサーとエフェクターは独自のポリシーを持っており、センサーの特性を最適に利用する方法を学習する。データはプラットフォーム上の中央長期メモリ構造を介して交換され、そこからすべてのポリシーが読み出すことができ、すべてのポリシーが書き込むことができる[14]。ポリシー間の協力はスティグマー信号によって媒介される。予想通り、結果として生じるプラットフォームの振舞いはかなり複雑で、新たなシナリオの微妙なニュアンスに適応する。
3.2 創発:協調の振舞いが技術的自律性の基礎を築く
統合問題解決(joint problem solving)における成功は、知覚とチーム内の他のエージェントとの相互作用がどのようにモデル化されるかに大きく依存する。上述したように、古典的な防空(AD)セットアップでは、さまざまなセンサーを介して情報を収集し、中央の指揮・統制(C2)ノードに伝達する。その後、命令や指示が指揮系統を伝わって、個々のエフェクターシステム(我々の場合は対空砲兵(AAA)プラットフォーム)へと流れていく。このアプローチは試行錯誤が繰り返されているが、いくつかの問題もある:
- ネットワーク中心主義(Network centricity)。このプロセスは、ネットワークを介した指揮・統制(C2)ノードとのデータ伝送に大きく依存しており、指揮・統制(C2)ノードは、自衛モードで運用されている場合を除き、主に個々のプラットフォームを調整する。通信が途絶え、帯域幅が制限されたらどうなるか。通信が途絶えた場合、効果的な協力のためにローカル・エンティティを再編成する他の方法はあるのか?
- センサーからエフェクターまでの遅延。データ・フュージョンのために指揮・統制(C2)ノードを必要とするネットワークを通じて情報を伝播することは、センサーからエフェクターまでの待ち時間を発生させる。この遅延は、入ってくる脅威の検知が遅すぎた場合、個々の防空(AD)プラットフォームを危険にさらす可能性がある。シングル障害点(single point of failure):指揮・統制(C2)ノードはシングル障害点(single point of failure)となる可能性がある。対戦相手が指揮・統制(C2)ノードを検知し、破壊することに成功した場合、防空(AD)ネットワーク全体が機能しなくなるか、少なくとも大幅な機能低下を招く。
- 再構成(Reconfiguration)。指揮・統制(C2)ノードが影響を受けなくても、ネットワーク内の個々のセンサーやエフェクターが失われると、化合物(compound)の再編成が必要になる場合がある。現在のところ、これには再計画策定が必要であり、再び遅延が発生する。消耗シナリオ(attrition scenarios)を考慮すると、一部のネットワーク要素が自動的に再編成できるようになれば、全体的な回復力と有効性が大幅に向上すると考えられる。
- アドホックなサポート(Ad-hoc support)。攻撃者は一般的に「相対的強さの原理(relative strength principle)」を利用する。これは、攻撃者が防御側の特定の狭い地点に戦力を集中させ、一時的に圧倒しようとすることを意味する。防御側が取組みを大幅に強化したとしても、攻撃地点の戦力がすぐに弾薬を使い果たしてしまうことはほとんど避けられず、一方、防衛インフラの大部分はほとんど影響を受けない。局所的に再編成できるシステムであれば、激しい攻撃を受けている部隊にアドホックな支援を提供し、より迅速に強化することができるのではないか、と我々は推測している。
- 取組みの経済性(Economy of effort)。統合防空システム(IADS)の複数のシステムが同じ空域をカバーする。実際には、これらのシステムはそれぞれ独自の指揮・統制(C2)構成物を持っている。これらの指揮・統制(C2)の構成物は、取組みの経済性が保たれるように、どのエフェクターを展開するかを決定または交渉する必要がある。この決定は、非常に文脈に敏感である[15]。我々は、この文脈を適切に理解するシステムが、脅威に見合ったより効果的なエフェクターの選択を行うことができると想定している。
これらの仮説を探るため、我々の目標は、指揮・統制(C2)構成物を全く持たないセットアップを実験することだった。むしろ我々のシステムは、個々の防空(AD)プラットフォームで構成され、どのように協力し、どのような脅威に対しても効果的で創発的な防衛反応を見つけるかを学習する[16]。要するに、我々は、同じチーム内の他のエージェントが協力するように動機付けるポリシーを学習することに努めている。そのために、対空砲兵(AAA)プラットフォーム間の統合の振舞い(joint behavior)を「分散型部分観測マルコフ決定プロセス」(DecPOMDP)※5としてモデル化する。
※5 「部分観測マルコフ決定過程(POMDP)」は、マルコフ決定過程(MDP)の一般化であり、状態を直接観測できないような意思決定過程におけるモデル化の枠組みを与える。「部分観測マルコフ決定過程(POMDP)」 は実世界におけるあらゆる逐次的な意思決定過程をモデル化するのに十分であり、ロボットのナビゲーションや機械整備 (machine maintenance)、および不確実な状況下でのプランニングなどに応用されている。適用する対象が分散している場合のマルコフ決定過程(MDP)を「分散型部分観測マルコフ決定プロセス」(DecPOMDP)という。
一般的な考え方は、エージェント間の「心の理論(theory of mind)」を発展させることである。すなわち、エージェント間の行動はコミュニケーション行為であると仮定する。エージェントは、仲間のエージェントの行動を観察したときに、その行動を解釈することができ、他者に最大限の情報を伝えるためにどのような行動をとるべきかを学習することができる[17]。その結果、エージェントは、統合の到達目標や個別の到達目標を達成するために、いつ、何を伝え合うのが最適かを学習する[18]。技術的な観点から、主な課題は、他のエージェントの現在の状態に関するあるエージェントの信念が、現在の状態と観察された行動だけでなく、探索されたポリシーにも依存するため、通常のように行動空間ではなく、ポリシー空間を探索するように学習手順を拡張することだった。
最初の訓練の結果は、パフォーマンスが大幅に不安定であることを示した。訓練のパフォーマンスは良好なパフォーマンスのレベルに達したものの、エージェント・チームにわずかな変更を加えると、パフォーマンスは急激に悪化した。我々の分析によると、エージェントは「特異な[19]」振舞い(“idiosyncratic” behavior)を学習することがわかった。訓練プロトコルを変更し、クロス・プレイとリーグ戦のスキームを実装すると、成績は安定した。詳細については後述するが、我々の予備的な結果からも明らかなように、この結果もまた、上記で示したレジリエンス仮説を立証するものであった。低通信帯域幅の制約や電子戦(EW)条件下で最適な通信パターンとタイミングを学習できる可能性があるため、システムのさらなる調査と訓練が必要である。
3.3 GhostPlayのシミュレーションへのアプローチ
イン・プロセス戦闘シミュレータは、GhostPlay環境の中心的な部分である。このシミュレータは、ステージ化されたウォー・ゲーミング・シナリオにおけるオブジェクト間の相互作用を編成する。シミュレータの計算能力は、かなり多数のエンティティを含むシナリオを数千の時間ステップにわたって迅速にプレイする必要があるため、重要な鍵となる。そのため、シミュレータは「イン・プロセス(in-process)」で展開でき、ネットワークの待ち時間なしに学習対象のオブジェクトと直接対話できるように構築された。シミュレータはまた、複数の時間分解能でシナリオを再生するための予防措置も備えている。
このシミュレータは、シナリオに新しいオブジェクトを追加することによって水平方向に拡張可能であり、個々のモデルをより詳細に拡張することによって垂直方向に拡張可能である。低解像度のシナリオをプレイしている間、シミュレータは主に確率論的モデル(相互作用効果の要約統計量を表す)を使って動作し、接近阻止/領域拒否(A2/AD)状況で発生するような時間的に拡張されたシナリオをターゲットとする。より高い解像度のモデルを装備することで、対空砲兵(AAA)砲塔の動きや個々のセンサー統制の機械的な待ち時間をモデル化するレベルまで、作戦的振舞い(operational behavior)を特定している。
3.4 予備的な結果
GhostPlayの予備的な結果は心強い。シミュレーションに基づく研究を1年弱続けた結果、防空(AD)構成物が斬新な振る舞いをすることが確認された。この新しいパターンは、以下に述べるように、戦争の原則の中核をなすものである。
シングル・プラットフォーム戦術
GhostPlayは、意図的にシングルの防空プラットフォームをモデル化することから始め、ドイツの対空砲兵(AAA)システムであるゲパルト自走高射砲(FlakPz Gepard)を使用した。ゲパルト(Gepard)はまた、移動中のターゲットを交戦しながら、搭載されたアクティブ・センサー(索敵レーダーと追尾レーダー機能)とパッシブ・センサー(光学ペリスコープと赤外線センサー)とエフェクターを作動させる防空(AD)システムを必要とするGhostPlayのシナリオに最も適している。また、センサーとエフェクターの追加機能に応じてプラットフォームの振舞いが適応するかどうかを分析するために、さまざまな調整ポリシーを実験したいと考えた。そのため、シミュレーションでは、対空砲兵(AAA)に仮想的な追加センサー(赤外線センサーなど)とエフェクター能力を装備させた。また、学習されたポリシーが、複数のソースからの情報を使用して融合された認識された航空写真(RAP:Recognized Air Picture)を利用するかどうかも知りたかったため、リンク・ベースで中央から供給される認識された航空写真(RAP)をシステムに提供した。
このシングル・プラットフォームのセットアップは、以下のような一連の興味深い発見をもたらした[20]。
- システムはセンサー統制戦略を学習し、ターゲット分類を改善する。例えば、従来は、AI分類器がペリスコープ・カメラによって生成されたビデオ・フレームを受け取り、ターゲットを分類していた。対照的に、GhostPlayポリシーを使用する潜望鏡は、まず、安定した分類へのより速い収束につながるように、関心のある特定の座標にズームインする方法を学習する[21]。
- システムはマルチ・センサー統制戦略を学習する。システムは、パッシブ・センサーに大きく依存する場合と、アクティブ・センサーを配備して放射線追尾型ミサイルに探知・攻撃されるリスクを最小化する場合の、状況に応じたトレードオフを実施するポリシーを学習することができる[22]。
- システムは、認識された航空写真(RAP)が利用可能になると振舞いを変えることを学習する。同じシナリオでも、認識された航空写真(RAP)が確保された状況認識に基づいて行動すると、システムは異なる行動をとる。振舞いの変化(behavioral changes)は、パッシブ・センサー(潜望鏡)の使用において最も顕著である。これらのセンサーは、全球航空写真が利用できない場合、主に360°の捜索に使用される。例えば、機械的な制約のためにプラットフォームが旋回するのに最も時間が必要な場合や、脅威の到来を予期して早期に砲塔の位置を調整するような場合に、捜索方向がインシデントに集中する。
- システムは優先順位を学習する。システムはターゲットとの交戦の優先順位を学習する。我々は105機の無人航空機(UAV)のスウォームを使用した。スウォームはスウォームのフォーメーションで飛行し、防空(AD)システムの少し手前で解散して個別攻撃を仕掛けた。最も厳しいシナリオでは、105機の個々の軌道は対空砲兵(AAA)センサーを混乱させるものだった。スウォームが解散した瞬間、高速の脅威が別の角度から対空砲兵(AAA)システムに接近した。このシステムは、第一に、高速の脅威を検知すること、第二に、この脅威が無人航空機(UAV)のスウォームよりもはるかに深刻であることを認識すること、第三に、無人航空機(UAV)のスウォームが派手な機動を続けている間に、この脅威と交戦するために砲塔と兵器を旋回させること、という課題をマスターした。
- 射撃統制ポリシーは適切なタイミングを学習する。システムは、兵器を配備するプラットフォーム(攻撃ヘリや非搭乗型航空機(UCAV)など)と徘徊型弾薬(loitering ammunition)を識別するポリシーを学習する。一般的に、学習されたポリシーは、エフェクターの届く範囲にある場合、徘徊型弾薬(loitering ammunition)をより遅く、兵器を搭載した車両をより早く交戦する傾向を示す[23]。
- 射撃統制ポリシーは、無人航空機(UAV)のスウォームによる低いセンサー分解能または「追跡の遺失(track drops)を」補償する。特に小規模の無人航空機(UAV)による攻撃(例えば、消耗攻撃(attrition attacks))では、センサー・システムとトラッカーは、各無人航空機(UAV)を個別に解決することができないか、またはスイッチング・トラックを生成したり、再初期化に必要なトラックを失ったり、落としたりする可能性がある。我々は、学習された射撃統制ポリシーがこれらの問題に比較的に頑健であることを観察する。このポリシーは、トラックは比較的に広い共分散を持っている場合でも、徐々にスウォームのサイズを減らすために、一連の調整された弾幕射撃パターン(barrage fire patterns)で「パルク(pulk)」と係合するように学習する。さらにテストが進み、この振舞いが実証されれば、センサーの質は対空砲兵(AAA)システムにとってそれほど重要ではなくなる一方、遠隔センサー(例えば、他のプラットフォームからのセンサーや前方に配備されたセンサーを使用)を使用してこれらのシステムを運用する機会は大幅に増加するだろう。
バイラクタルTB2(Bayraktar TB2)のようなシングルの無人航空機(UAV)/非搭乗型航空機(UCAV)から、ドローンのスウォーム、Ka-52やMi-28に代表されるヘリコプター攻撃と高速接近ミサイルの組み合わせまで、様々な脅威に対して対空砲兵(AAA)プラットフォームを訓練した。攻撃者は「ローカル・ルール・ベース・インテリジェンス(local rule-based intelligence)」、つまり、攻撃パターンと目標は事前に定義され、事前に指定された接近軌道でモデル化された。しかし、攻撃者は、防空(AD)システムの検知と交戦にどのように対応するかを規定したモデル化されたルールセットに基づいて行動した[24]。すべてのモデルには確率論的損害モデルが関連付けられ、ターゲットの物理的構造、エフェクターのタイプ、および衝突領域が与えられた場合に、ターゲットのオブジェクトに対する現実的なエフェクターの衝突推定を可能にした。
予備的な結果によると、対空砲兵(AAA)プラットフォームは様々なタイプの脅威に対して非常にきめ細かい交戦戦術を学習し、ターゲットを破壊することが重要な場合、あるいは無効化することだけが重要な場合さえも感知する。伝統的なOODAワークフローの実装と比較して、我々のシステムは、割り当てられたオブジェクトを防護するために必要な弾薬の量を、ヘリコプターに対して約12%削減し、攻撃スウォームに対するシナリオでは最大42%削減する[25]。プロジェクトでは、これらの数値をさらに拡張・検証し、プロジェクトの中間報告で詳細なレポートを発表する予定である。我々は、シミュレーション環境の公開や、ベンダーがそれぞれの統制戦略を比較できるテストベッドの確立を計画している。
マルチ・プラットフォームの戦術
シングル・プラットフォームのシナリオに加え、我々はシナリオ固有の高価値アセット(HVA)として飛行場を防護するために、同じタイプの複数の対空砲兵(AAA)ユニットを組み合わせた。これらの訓練の意図は、複数の対空砲兵(AAA)システムが中央の指揮・統制(C2)調整なしに自由にチームを組むことを学ぶことによって、何が予想されるかを最初に洞察することであった。我々は以下の予備的な結果を得た:
- 対空砲兵(AAA)プラットフォームのグループは、30機の無人航空機(UAV)からなるドローンのスウォームを防御するために協力することを学んだ。対空砲兵(AAA)プラットフォームの協力戦術はすでにかなり複雑になっていた(図2)。対空砲兵(AAA)プラットフォーム1はアクティブ・センサーを使用し、プラットフォーム2と3は放出統制(EmCon)で状況を観察していた。10機の無人航空機(UAV)が対空砲兵(AAA)プラットフォーム1と交戦するためにスウォームから分離すると、20機の無人航空機(UAV)が主なターゲットである飛行場へとさらに進んだ。対空砲兵(AAA)1が攻撃してくる無人航空機(UAV)のスウォームと交戦している間、対空砲兵(AAA)2はメインのスウォームのそばに忍び込もうとした。一方、対空砲兵(AAA)3は「レームダック(lame duck)」のふりをした。無人航空機(UAV)のスウォームが攻撃を開始する直前、対空砲兵(AAA)2と3は同時にメインのスウォームと交戦した。その結果、対空砲兵(AAA)2の移動がスウォームの機動の自由(freedom of maneuver)を著しく制限する状況を作り出し、効果的に無力化できることが判明した。防空(AD)システムがこのポリシーを採用していなかったシナリオの30%で、スウォームが優勢となり、飛行場に大きな損害を与えた。対照的に、このポリシーを使用した対空砲兵(AAA)チームは、プレイした全シナリオの98%でスウォームを上回り、飛行場を守った。
| 図2:対空砲兵(AAA)プラットフォーム(青)は、侵略者のスウォーム(赤)から飛行場を守る。
FlakPz:自走高射砲 UAV Swarm:無人航空機のスウォーム 出典:GhostPlayのビデオ素材から |

- 再編成による残存性の向上さらなるテストでは、消耗攻撃の効果を調査し始めた。我々は105機の無人航空機(UAV)のスウォームから高価値アセット(HVA)を守るために10機の対空砲兵(AAA)システムを使用した。10基の対空砲兵(AAA)システムは高価値アセット(HVA)の周囲に配置された。つまり、70~90機の無人航空機(UAV)が地理的に狭い地域に集中し、その地域に配備された2~3機の対空砲兵(AAA)システムにとって圧倒的な戦力となる。並行して、より小型の無人航空機(UAV)のスウォームが対空砲兵(AAA)システムの注意をそらし、陣地で忙しくさせようとする。集中した戦力により、シナリオでは対空砲兵(AAA)システムの損失は避けられなかった。初期の訓練段階では、対空砲兵(AAA)ソリューションは失われ、生き残った無人航空機(UAV)の数は高価値アセット(HVA)を攻撃するのに十分な数であった。ポリシーの後の段階では、対空砲兵(AAA)プラットフォームは継続的にグループ割り当てを再編成し、ターゲットを再優先することを学んだ。その結果、1つの対空砲兵(AAA)システムが機能不全に陥るたびに、別の対空砲兵(AAA)プラットフォームが移動し(対空砲兵(AAA)プラットフォームが弾薬不足に陥ったときには、先制的であっても)、無人航空機(UAV)のスウォームは実質的に壊滅し、高価値アセット(HVA)に実質的な危害を加えることができなくなった。全体として、10,000のシナリオのうち9,864において、10機の対空砲兵(AAA)からなるコンステレーションは、105機の無人航空機(UAV)のスウォームに対して効果的な防御を行うことができ、3機以上の対空砲兵(AAA)プラットフォームを失うことはなかった。
これらは理想化された仮定に基づく初期の予備的な結果であることを強調する必要がある。例えば、シナリオでは、対空砲兵(AAA)プラットフォームが内部状態情報を共有し、放出統制(EmCon)のルールに従うことなく自由にセンサーの配置を選択できると仮定している。さらに、対空砲兵(AAA)プラットフォームは、その位置から移動するための制限を持たず、交戦規則(RoE)に縛られることもなかった。今後さらにシミュレーションを行い、交戦規則(RoE)の違いが対空砲兵(AAA)プラットフォームの機動の自由(freedom of maneuver)にどのような影響を与えるかを検討する予定である。また、対空砲兵(AAA)プラットフォームがすでに達成した成果を発揮することを妨げることなく、効果的な人間による統制を確保するために、交戦規則(RoE)をどのように作成する必要があるかを精査する。
さらに、技術的な注意点もいくつかある。一方では、中央の調整なし[26]にフェデレーションで複数の対空砲兵(AAA)プラットフォームを運用しても、意味のある結果が得られるかどうかは決して確実ではない。一方では、すべての対空砲兵(AAA)プラットフォームが、エフェクターの到達範囲(reach)に同じターゲットがあるとすぐに飛びつく可能性があり、利用可能な能力を非常に非効率的に使うことになる。我々の予備的な結果は非常に心強いものであったが、我々は、チームのローテーション、アザープレイ(other-play)※6、およびリーグアップデートのような学習プロトコルを使用することにより、安定したポリシーを学習するための予防策を講じた。「観測可能なマルコフ決定プロセス(POMDP)」の条件を破り、不安定な振舞い(instable behavior)につながる可能性のある暗黙のコミュニケーション行為について、ポリシーが学習しないことを保証するために、さらなる研究が必要である。不完全な知覚モデルや「戦争の霧(fog-of-war)」効果のシミュレーションを考えると、後者はコンピュータ・ゲームに比べてかなり困難である可能性があり、今後のプロジェクト・フェーズでさらなる取組みが必要となるだろう。
※6 人工知能の深層学習の方法には、セルフプレイ(self-play)と呼ばれるエージェントを使用するものがある。これは、AlphaGoのように、自分自身で対戦することで戦略を学習するAIエージェントである。一方で、AIエージェントが初めて遭遇する他のエージェントとの協調を学習する方法があり、そのAIエージェントのことをアザープレイ(other-play)エージェントという。
3.5 まとめ
最初の発見は、学習されたポリシーが重要な戦争の原則(principles of war)を反映する振舞いのパターン(behavioral patterns)を作り出すことができることを示唆している。センサー・エフェクター・ネットワークをよりきめ細かく統制することで、効果的な防護(目標)を確立するために必要な兵力の量を減らすことができる(兵力の経済性)。我々の対空砲兵(AAA)システムは、ターゲットのオブジェクトのキネティックな側面だけでなく、より多くの情報を考慮することで、プラットフォーム・レベルでの状況認識を向上させます。これにより、プラットフォームは敵の動きを予測し、創発的かつ適応的な対抗策を可能にする。この動作により、敵が対空砲兵(AAA)システムを「読んで(read)」理解することは不可能となる。したがって、防空側は、主導権を自らに有利な方向にシフトさせる新たな奇襲要素を利用することができる。
ネットワーク中心戦(network-centric warfare)を活用した防衛システムは、主にすべての構成物をシームレスに統合することにより、連合ソリューションを構築することに重点を置いている。我々の予備的な結果は、すべての構成物が、フェデレーションのすべての要素によって知られているポリシーに基づいて、仲間の現在の振舞い(current behavior)と将来の振舞い(future behavior)を解釈することができるように、認知がこれらのフェデレーションを大幅に増強しようとしていることを示している。これは、通信が欠落し、データが破損する可能性が高い非ベナイン環境において、レジリエンスを確保する新たな方法を提供するだろう。
4 倫理とパフォーマンスのバランス
民主主義国家では、軍隊(armed forces)は法の支配だけでなく、倫理的・道徳的原則によって定められた枠組みの中で活動する[27]。この枠組みの中で、軍隊(armed forces)は遅かれ早かれ技術的自律性に取り組むことになる。この文脈において、防衛AIは武力行使に役立つため、重大な懸念を引き起こす。したがって、防衛AIが民主主義国家の防衛に使われるのであれば、それは必然的に国内法および価値志向の枠組み、関連する超国家的ルール、国際法に組み込まれなければならない。しかし実際には、法的、倫理的、社会的規範をAIシステムの機能に組み込むことは大きな課題である。
2017年以降、政府機関や非政府組織は、AIシステムの一般的で必須の品質属性を概説するリストを作成している。これらのリストは、倫理的、法的、社会的、技術的配慮を組み合わせた最初の試みと見ることができる。しかし、これらのリストは、人間の尊厳や自由、平和と正義、あるいは祖国愛、真実性、勇気といった兵士としての美徳といった中核的価値を実現・促進するにはほど遠い。
従って、GhostPlayの重要な研究面は、2021年9月に発効したバリュー・ベース・エンジニアリング(VBE)の新規格IEEE 7000™ 2021の適用可能性を評価することである。理想的には、この規格を適用することで、質の異なる防衛ソリューションがもたらされる。そのためGhostPlayは、ドイツ軍(German Armed Forces)がその指導理念であるInnere Führung(内部指導)に帰結する価値観の全容を検討したいと考えている。GhostPlayは、IEEE 7000™-2021に完全に準拠するようにデザインされた世界初の防衛AIアプリケーションとなる[28]。
さらに、GhostPlayがIEEE 7000™規格を使用することで、システム開発における新しい職務内容である価値主導(Value Leads)を訓練するための学習教材が作成される。この価値主導(Value Leads)は、バリュー・ベース・エンジニアリング(VBE)に必要な哲学的・技術的理解を有しており、ドイツを価値に敏感な防衛AIエンジニアや開発者を育成するパイオニアかつ先進国にすることを到達目標としている。
5 イノベーション管理に対するGhostPlayのアプローチ
GhostPlayは、学術および応用研究からの最先端の洞察を用いて、連邦軍に斬新なレベルの戦術的多用途性を提供する能力・技術開発プロジェクトである。戦術的汎用性(tactical versatility)は、情報、意思決定、効果の優位性を目指すドイツ連邦軍を補完するものである。GhostPlayの主な付加価値は、文脈と結果を考慮したソリューションが、異なる軍事ドメインで使用されるアプリケーション間で移行できるという事実に由来する。これによって、ドメイン間や軍種間の相互受粉の貴重な機会が生まれる。
結局のところ、GhostPlayの厳しい開発課題には、アジャイルで総合的なイノベーション管理アプローチが必要なのである。この目的のために、GhostPlayはReal-Optionアプローチ[29]とアジャイル開発プロセスを組み合わせている。このアプローチでは、金融オプションの価格設定のような仮想的な価格設定スキームを採用し、期待される運用価値に応じて新しい研究と実装のトピックを評価する。このスキームでは、内部および外部のリスク要因が考慮されるため、リスクと機会のバランスがとれ、割り当てられた予算によって生み出される期待運用価値が最大化される。
実際、イノベーション・ポートフォリオは、「防衛AI観測所(Defense AI Observatory)」が収集・整理した最近の紛争、技術動向、西側勢力の最近の取り組みに関する外部情報と、業界パートナーが認識する実際の市場要件、および我々の研究プロジェクトの適切な調査結果を組み合わせて、半年ごとに評価される。
6 展望
1年後、GhostPlayは、防空(AD)環境における戦術的AIと創発的協調の実現可能性と潜在的な改善点を強調する心強い結果をもたらした。
すでにこの段階で、GhostPlayのプロジェクト・パートナーであるHensoldt社は、アクティブ・センサーとパッシブ・センサーの配備を戦術AIで調整するために、プロジェクトのセンサー・リソース管理機能を新しい環境に移行することを決定した。これは軍隊(armed forces)に新たな能力を生み出すものであり、プロジェクトの方法論と技術的アプローチの正当性を証明するものである。
さらに、現在攻撃システムに使用されているファジー論理※7基盤とする干渉モードを置き換えることで、GhostPlayに使用されている一連の原理を拡張する[30]。次の段階では、攻撃側は同じ戦術AIと創発原理を使用して、「カウンタープレイ」訓練プロトコルで任務中に新しい戦術を開発したり、既存の戦術を変更したりする。これは、防空(AD)システムと敵防空制圧(SEAD)システムが交互に訓練されることを意味する。より成功する防空(AD)ポリシーが発見されるたびに、敵防空制圧(SEAD)ポリシーは新しい防空(AD)ポリシーを克服するために適応され、その逆もまた然りである。このような「対戦型(opponent-play)」サイクルを繰り返すことで、双方がますますきめ細かく複雑な振舞い(fine granular and complex behavior)を継続的に学習し、ある段階で今日の最も危険な脅威に対処できるようになる。
※7 ファジー論理とは、システムの予想される出力が「真」または「偽」だけではない場合に適用できる手法で、つまり、不確実性(真実度)に関するものである。別の意味では、ファジー論理は人間の推論、意思決定および人間のような思考の数学的モデリングのことをいう。
AIに基づく敵防空制圧(SEAD)戦術は、現在の能力ギャップに直接対処するものであるため、特に関心が高い。S400やS500の防空(AD)化合物のような高度な脅威に対する敵防空制圧(SEAD)戦術を開発するために、既存の防空(AD)能力を地対空ミサイルモデルで補完し、大規模な「観測可能なマルコフ決定プロセス(POMDP)」手法による計画策定で今日使用されている純粋に反応的なRLアーキテクチャを拡張することができる。
GhostPlayの多くの側面は、作戦運用に入る前に、堅牢性や効果の面でさらなる研究と分析を必要としているが、このプロジェクトは、さまざまな軍事的任務のための付加価値を生み出している:
- 将来の戦力計画策定のための非従来型のレッド・チーミング。GhostPlayシミュレータとAIモデルは、新しいセンサー/エフェクターの組み合わせをテストするために使用することができる。GhostPlayは、AIが利用可能な物理的能力の最適な使用方法を学習する最初の環境を提供する。これは、新しいセンサー、エフェクター、通信、プラットフォームの能力が将来の戦術にどのような影響を与えるかについての高度な洞察を戦力計画担当者に提供する。したがって、このシステムは、最適な能力の組み合わせを見つけ、新しいシステムの運用要件を効率的に開発するために使用することができる。
- 現在開発中のプロジェクトに対する、非従来型のレッド・チーミング。GhostPlayは、システム・ベンダーが予測困難な敵対者(hard-to-predict adversary)に対してコンセプトや戦術をテストするためのテストベッドを提供することができる。現在、新しいシステムは軍事アナリストが作成したシナリオやビネットに対して評価されているが、シナリオの選択は同盟国のドクトリンや予想される敵対的振舞い(adversarial behavior)に関する同盟国の考え方に偏っている。対照的に、GhostPlayは「モデルなし(model-free)」で動作し、事前に選択されたビネットなしで戦術的振舞い(tactical behavior)を学習する。このアプローチは、まだ実践でも既存のモデルでも見られない振舞いのパターン(behavioral patterns)を提供するため、既存のテストベッドを補強し、同盟国のシステムをよりよく準備し、開発中のシステムの未知の弱点を発見する可能性がある。
- 搭乗員訓練のための非従来型のレッド・チーミング。DIS(IEEE)※8フレームワークでセットアップされたGhostPlay構成物は、パイロットや防空シミュレータに統合することができ、まだ見ぬ戦術で乗組員を訓練することができる。
※8 DIS とは、分散インタラクティブ・シミュレーション(Distributed Interactive Simulation)のことで、複数のホスト・コンピューター間でリアルタイムのプラットフォーム・レベルのウォー・ゲームを実行するためのIEEE標準のこと。
- GhostPlayを他のドメインや任務分野に転用する。GhostPlayのアプローチとポリシーは、中央の指揮・統制(C2)構成物なしで複雑な迎撃任務を調整することを意味する防衛ソリューションの開発を支えることができる。これにより、海軍プラットフォームを地表や海底の脅威から防護する斬新なソリューションが提供され、例えば統合戦術火力支援(JTFS:Joint Tactical Fire Support)を提供するソリューションが強化される可能性がある。
最後に、GhostPlayのパートナーは、「GhostPlay light」環境、つまり、より忠実度が低く、センサーのモデルも特定されていないシミュレーション環境のデジタル・ツインを運用する可能性も考えている。「GhostPlay light」は、市販のビデオ・ゲームに接続することができる。その意図は、多くのプロ、セミプロ、ホビー・パイロットを巻き込んで「群衆の知恵(wisdom of the crowd)」を活用し、新しい非従来型の戦術(new and unconventional tactics)を検出することである。そして、これらの新しい戦術は、GhostPlayに立ち向かい、改良するために使用することができる。それぞれの結果は、現実的なセンサーモデルを運用する軍隊(armed forces)の制限されたシミュレーション環境に移すことができる。
文献
Borchert, Heiko, Torben Schütz, Joseph Verbovszky, Beware the Hype. What Military Conflicts in Ukraine, Syria, Libya, and Nagorno-Karabakh (Don’t) Tell Us About the Future of War, Hamburg, Defense AI Observatory, 2021, https://defenseai.eu/daio_beware_the_hype (last accessed 31 August 2022).
Ernest, Nicolas et.al, “Genetic Fuzzy based Artificial Intelligence for Unmanned Combat Aerial Vehicle Control in Simulated Air Combat Missions,” Scholar@UC, 8 February 2017, https://scholar.uc.edu/concern/articles/bc386t25c?locale=en (last accessed 31 August 2022).
Foerster, Jakob N. et. al., “Learning to Communicate with Deep Multi-Agent Reinforcement Learning,” archiveX, 21 May 2016, https://arxiv.org/abs/1605.06676 (last accessed 31 August 2022).
Graves Alex. et.al., “Hybrid computing using a neural network with dynamic external memory,” Nature, 20 October 2016, pp. 471-476, https://www.nature.com/articles/nature20101 (last accessed 31 August 2022).
Horowitz, Michael C. and Shira Pindyck, “What is a military innovation and why it matters,” Journal of Strategic Studies, 2022, https://doi.org/10.1080/01402390.2022.2038572 (last accessed 31 August 2022).
Isci, Hasan, Gülay Öke Günel, “Fuzzy logic based air-to-air combat algorithm for unmanned air vehicles,” International Journal of Dynamics and Control, 10:1 (February 2022), pp. 230-242, https://link.springer.com/article/10.1007/s40435-021-00803-6 (last accessed 31 August 2022).
Kanerva, Pentti, Sparse Distributed Memory (Boston, MIT Press, 1988).
Science and Technology Trends 2020-2040. Exploring the S&T Edge (Brussels, NATO Science and Technology Organization, 2019).
Sun, Yi, Daan Wiestra, Tom Schaul, and Jürgen Schmidhuber, “Stochastic search using the natural gradient,” ICML 09: Proceedings of the 26th Annual International Conference on Machine Learning, 2009, pp. 1161-1168, https://doi.org/10.1145/1553374.1553522 (last accessed 31 August 2022).
Trigeorgis, Lenos, Real Options. Managerial Flexibility and Strategy in Resource Allocation (Cambridge, MIT Press, Cambridge, 1999)
UK Defence Doctrine, Joint Doctrine Publication 0-01 (Shrivenham: UK Ministry of Defence/Development, Concepts and Doctrine Center, 2014.Uppal, Rajesh, “Israel successfully tests multilayered air defense system to defend against barrage of short-,medium-, and long-range ballistic missiles,” IDST, 15 May 2022, https://idstch.com/geopolitics/srael-successfully-tests-multilayered-air-defense-system-to-defend-against-barrage-of-short-medium-and-long-range-ballistic-missiles/ (last accessed 31 August 2022).
Wiestra, Daan, Tom Schaul, Tobias Glasmachers, Yi Sun, Jan Peters, Jürgen Schmidhuber, “Natural Evolution Strategies,” Journal of Machine Learning, 15 (2014), pp. 949-980, https://jmlr.org/papers/v15/wierstra14a.html (last accessed 31 August 2022).
Work, Robert O. and Shawn Brimley, 20YY. Preparing for War in the Robotic Age (Washington, DC, Center for a New American Security, 2014), https://www.cnas.org/publications/reports/20yy-preparing-for-war-in-the-ro-botic-age (last accessed 31 August 2022).
ノート
[1] Work/Brimley, 20YY.
[2] Science and Technology Trends 2020-2040.
[3] Horowitz/Pindyck, “What is a military innovation and why it matters.”
[4] Borchert/Schütz/Verbovskzy, Beware the Hype, p. 13-17.
[5] Ibid., pp. 43-44.
[6] UK Defence Doctrine, p. 28, 30-31, 50-51
[7] 産業環境では通常、照明のような統制可能な環境条件を作り出そうとする。 例えば、コンベヤを降りてくるオブジェクトは常に同じ光で感知され、コンベヤベルトの搬送に対する外部からの悪影響を制限/排除する。
[8] これは分類器が悪いのではなく、与えられたセンサー入力でターゲットを分類することができないという事実が原因であることに注意されたい。
[9] システムはセンサーを通して環境を知覚しており、不完全な知覚しか持っていないため、マルコフ決定過程(MDP)の真の状態を正しく観測することは想定できない。むしろ、これまでの観測のシーケンスから真の状態を推定し、部分的に再構築することで、タスクがさらに複雑になり、部分的に「観測可能なマルコフ決定プロセス(POMDP)」になる。
[10] 短期的な報酬獲得と長期的な目標とのバランスをとることは、「時間的信用割り当て問題(temporal credit assignment problem)」の一部である。実際の実装には、「行動(action)」を構成するものの巧みなエンジニアリングが必要である。例えば、トラッカーが妥当な精度でトラックを初期化し、維持できるようにすることなどである。我々は現在、特定のタスクの完全な実装を提供するマクロ・アクションに取り組んでいる。さらに、「検出前に追跡(track-before-detect)」と「注意に基づく追跡(attention-based tracking)」を組み合わせて実験しており、これらの訓練されたモデル・フリーのバリエーションが、高待遇のシナリオにおいて、より迅速なエフェクターの交戦と、より優れた自己防御を可能にするかどうかを分析している。
[11] https://www.darpa.mil/about-us/darpa-perspective-on-ai (last accessed 31 August 2022).
[12] AI分類器は通常、チュートリアル学習を使用する。この場合、即時のチュートリアル入力は、誤差信号を形成するために使用され、誤差に最も寄与したパラメータを調整するために、分類器に逆伝播される。
[13] Graves, “Hybrid computing using a neural network with dynamic external memory;” Kanerva, Sparse Distributed Memory
[14] このアルゴリズム・ソリューションは、21strategiesが独自に開発したもので、商用ドメインで長年使用されている。関連コンセプトについては Sun/Wiestra/Schaul/Schmidhuber, 「自然勾配を利用した確率的探索」; Wistra/Schaul/Schmidhuber, 「自然進化戦略」を参照。
[15] 取組みの経済性は、15万米ドルもする砲撃ミサイルを800万米ドルもする防空(AD)ミサイルで攻撃することが経済的でないことを示唆している。取組みの経済性に従わないことは、防衛能力と復元性の甚大な損失に早変わりするかもしれない。
[16] これはかなり過激な立場だ。我々は、実際の配備には特定のデータ集約ノードや指揮ノードが含まれると考えているが、個々のシステムはそれらがなくても動作するが、もし利用可能であれば、それらを最適に利用することができる。
[17] フォルスター著「マルチエージェント深層強化学習によるコミュニケーションの学習」
[18] エージェントの行動を定義する探索されたポリシーは、チーム内の全エージェントにとって共通の知識であると仮定される。
[19] 例えば、対空砲兵(AAA)エージェントが探索レーダーのスイッチを入れるのが観察された。プラットフォームはパッシブ・センサーとネットワーク化された認識された航空写真(RAP)でほとんど動作することを学んだので、他のエージェントは、プラットフォームが攻撃されていることを合図したいことを示唆する行動だと考えた。この解釈はまったく直感的でないわけではない。しかし、一般的には、探索レーダーのスイッチは、プラットフォームがその近傍の周囲についてより多くの情報を取得したいことを意味するだけであり、プラットフォームが攻撃を受けていることを自動的に示唆するものではない。もし他のエージェントがこのような行動を誤って解釈した場合、彼らは送信しているプラットフォームに向かって移動し、助けるかもしれない。
[20] 認識された航空写真(RAP)は、より強力で長距離のセンサーを使用し、より広い範囲のデータ融合プロセスによって生成される。認識された航空写真(RAP)の作成には、分類と識別の処理と人間による検証が含まれるため、より広い範囲の視界が得られるが、報告遅延が発生する可能性があり、そのような情報をローカル・センサーに関連付ける際に考慮する必要がある。
[21] DeepMinds AlphaStarと同様に、アクション・スペースはアクション・マクロで実装されている。つまり、システムは最初にアクションのタイプを決定する(例えば、センサー統制、エフェクター統制、センサー番号、その後のすべてのフィールドは、アクション・マクロの文脈で解釈される)。自走高射砲(FlakPz)を(TwinVisのような)パッシブ・センサー・ネットワークに接続し、パッシブ・システムを予備誘導および事前警告システムとして機能させることは、興味深い新しい機会である。予備的な証拠によれば、この組み合わせは電磁放射を低減するため、自走高射砲(FlakPz)の残存性を大幅に強化できる可能性がある。
[22] いくつかのシナリオから得られた証拠は、追跡レーダーを使って、追跡ビームから逃れようとするターゲットの方向転換を誘発することをポリシーが学習したことを示唆している。しかし、これはより詳細に分析される必要があり、特に観測された振舞いが安定したものであり、単なる不要な人工物ではないことを確認する必要がある。この解析はプロジェクトの第2フェーズで行う予定で、そこでは現在のルール・ベースのアプローチとは対照的に、より精巧な空中ビークルの振舞いを使用する予定である。
[23] 今のところ、これは単なる観察に過ぎない。我々はまだこの振舞いを適切に分析していない。しかし、兵器を搭載し、訓練されたポリシーの以前の世代を使用するプラットフォームでのシナリオ実行を見ると、以前の交戦はプラットフォームによる兵器の放出を先取りする可能性があることを示唆している。「可能な限り早い(as-early-as-possible)」交戦は、レーザー誘導兵器のモデルを使用するプラットフォームとのシナリオでも発生しており、これは観察を裏付けるさらなる証拠として解釈できる。
[24] Isci/Günel著「ファジィ論理に基づく無人航空機の空対空戦闘アルゴリズム」で議論された原則に従い、差し迫った脅威に対する局所的な行動と、防空(AD)システムによって交戦中の攻撃の編成は、ファジー推論によってモデル化されたが、敵防空制圧(SEAD)ミッションに適応された。
[25] いくつかの無人航空機(UAV)スウォーム・シナリオでは、OODAワークフロー統制システムが必要とする余剰弾薬は主要な問題ではなかった。これらのケースでは、対空砲兵(AAA)プラットフォームは単にシナリオを生き残ることができなかった。
[26] 現実的な配備では、少なくともプラットフォームが積極的にターゲットに関与する担当分野が割り当てられている。
[27] 産業界が技術的な自律性の側面を積極的に研究しているように、例えば自律走行やロボット支援をサポートするために、これらの技術が軍事的な文脈で現れないもっともらしい理由はない。したがって、このような能力の効果と可能性は、将来の戦力計画策定という観点からも、潜在的な将来の脅威という観点からも、理解され、分析されなければならない。
[28] https://standards.ieee.org/ieee/7000/6781/ (last accessed 31 August 2022).
[29] Trigerios, Real Options.
[30] アーネスト著「模擬空戦ミッションにおける無人戦闘機統制のための遺伝的ファジィ・ベースの人工知能」